Also known as: Come look at my glorious piece of garbage!
I haven't had any sort of automated deployment for my personal projects since I stopped using Heroku a few years ago. I have had a bunch of different deployment systems since leaving Heroku, but for the past two years, my development workflow looked like the following:
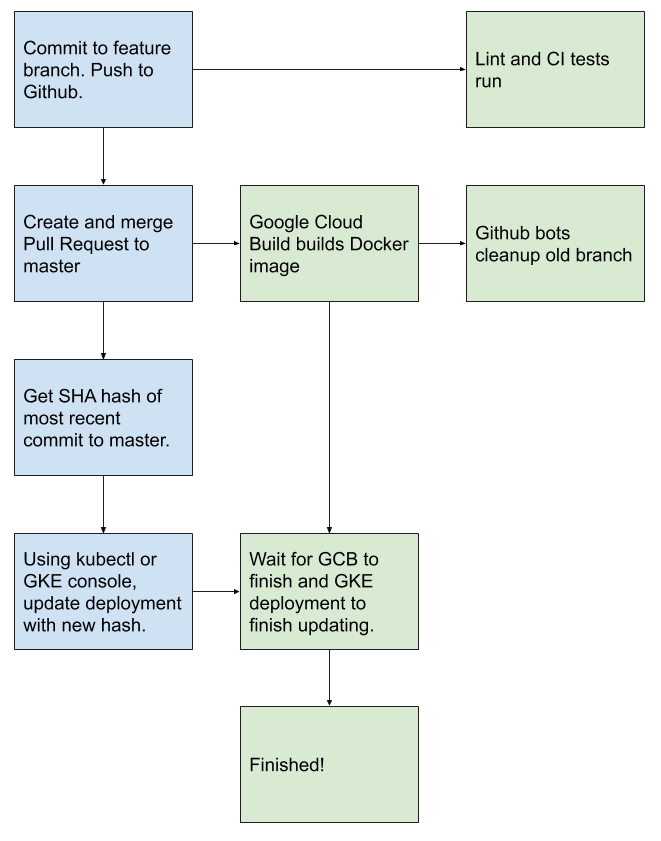
Which, was incredibly painful, because of a few reasons:
- It required me to do things manually after things were merged into master.
- I couldn't deploy things from my phone easily (I do small changes from my phone semi-frequently).
- Automatic updates to my git repos (I have some cron jobs that commit code every day for me) wouldn't deploy to GKE.
- I have ~30 sites and applications running on GKE, and I would semi-frequently post the commit SHA into the wrong app, which would mean the deploy would never happen.
So! I sat down and played with a few ideas, before I came up with a simple but efficient design. Before I walk through my solution, I want you to understand my production environment.
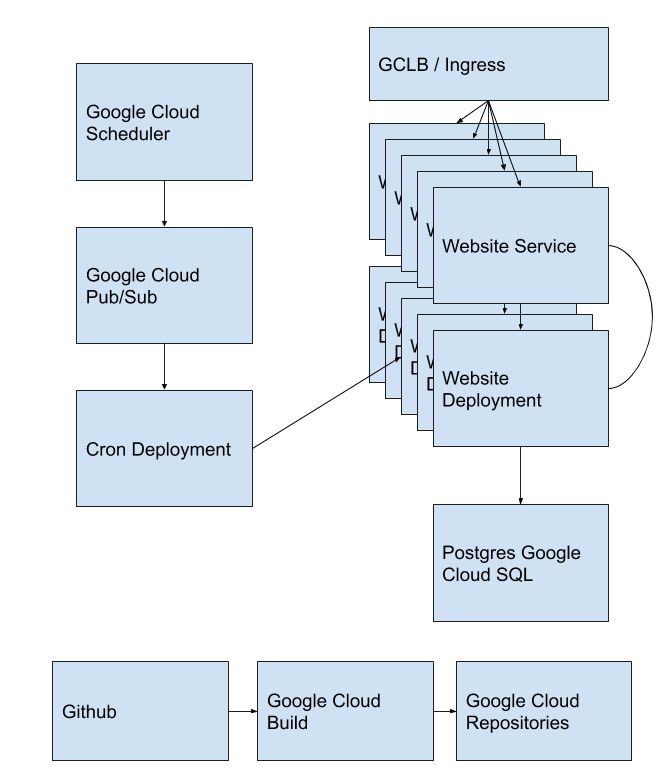
This drawing ignores a few things, mainly because I have a longer post on the overall architecture design coming soon, focused on keeping costs low. But the important details are:
- Every website gets a deployment and a service
- There is a Cron deployment which reads messages off of a pubsub queue, which is full of job requests from Google Cloud Scheduler. Each job request has a job name which the code then does. You can see the code for this at github.com/icco/cron.
- Many deployments talk to each other.
- There is a single postgres Cloud SQL, that a very small subset of services talk to.1
- Every git commit on GitHub I make triggers a Google Cloud Build job, which stores a Docker image in Google Cloud Repositories.
After exploring the GKE and Kubernetes docs, I discovered that you can grant deployments special privileges to the Kubernetes Master API, which means that you can have one container modify your entire cluster if you want. So given the above design and this new found information, I developed a new hook in my Cron code to query GitHub, get the most recent commit on master, and then update GKE.
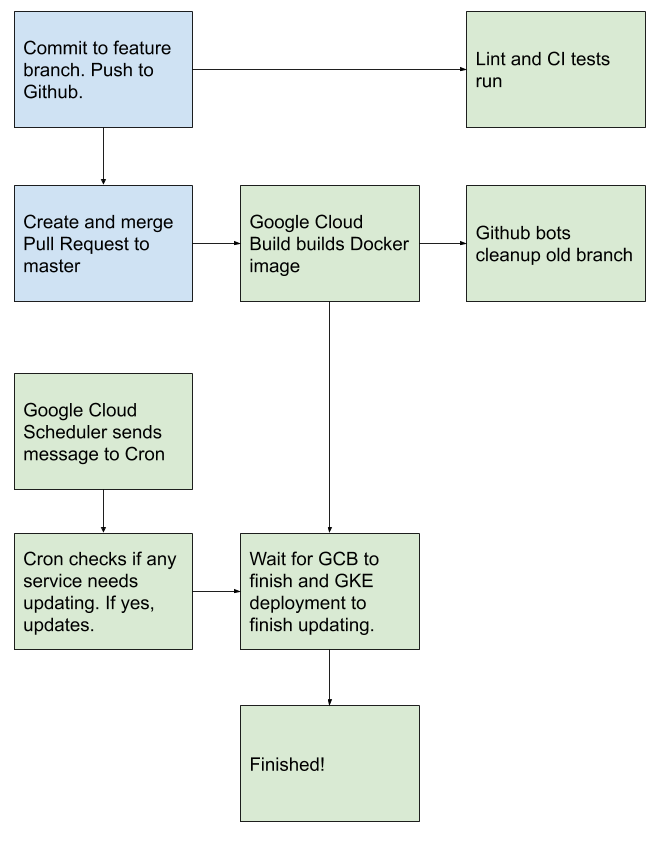 You can read the Go code that does the actual update at https://github.com/icco/cron/blob/8cba5454db6732756ba31df10ea8e284867d9252/updater/main.go#L140-L170, but the interesting thing here is giving permission to the Cron deployment to talk to the k8s master API. To do this, you'll need to create a Roll (i.e. a permission set), a service account (this is something you can assign to a pod or a deployment), and a roll binding to connect them.
You can read the Go code that does the actual update at https://github.com/icco/cron/blob/8cba5454db6732756ba31df10ea8e284867d9252/updater/main.go#L140-L170, but the interesting thing here is giving permission to the Cron deployment to talk to the k8s master API. To do this, you'll need to create a Roll (i.e. a permission set), a service account (this is something you can assign to a pod or a deployment), and a roll binding to connect them.
First, let's define the role.
kind: Role
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cron-role
namespace: default
labels:
app: cron
rules:
- apiGroups: ["apps"]
resources: ["deployments"]
verbs: ["get", "list", "update"]
The role has a name cron-role and is in the namespace default. The important section though is the rules. To find the correct API groups, you basically need to dig through the API documentation. The verbs are the actions on the resource that you can take.
apiVersion: v1
kind: ServiceAccount
metadata:
name: cron-service-account
labels:
app: cron
Nothing interesting is in the service account, besides the name, which we will need for the role binding.
kind: RoleBinding
apiVersion: rbac.authorization.k8s.io/v1
metadata:
name: cron-rolebinding
namespace: default
labels:
app: cron
subjects:
- kind: ServiceAccount
name: cron-service-account
roleRef:
kind: Role
name: cron-role
apiGroup: ""
Here we join everything together. All three of these things need to be in the same namespace to be able to work together. You should apply these with something like kubectl apply -f cron.yml.
Once these three exist, you can add the service account to the cron deployment.
My very simple cron deployment looks a bit like this:
apiVersion: apps/v1beta1
kind: Deployment
metadata:
name: cron
labels:
app: cron
spec:
replicas: 3
template:
metadata:
labels:
app: cron
tier: web
spec:
serviceAccount: cron-service-account
containers:
- name: cron
image: gcr.io/scrubbed/cron
ports:
- name: appport
containerPort: 8080
Now, once this config is applied, the cron deployment can talk to the k8s API and modify other deployments!
I now run this cron job once an hour, or I can trigger it manually through the GKE UI if needed for urgent deploys.
Now you may ask, why not use the CronJob deployment type in k8s? I have no good reason, beyond I like having everything look like a web server (I blame my time at Google for that weird tick). This way I have a set of servers always running and I can easily get logs and metrics from them just like I would the rest of my services. It's not perfect, but it works for me!
Hope you enjoyed this. I'm trying to write more technical stuff more often.
Feel free to tweet or DM me questions @icco on twitter, or email (nat@natwelch.com).
/Nat
#kubernetes #infrastructure #technical
Footnotes
-
Most services talk to a GraphQL server, github.com/icco/graphql, which talks to the database. ↩